The 2026 Rebuild of Telco Voice — Why Containers, Automation and AI Are Needed
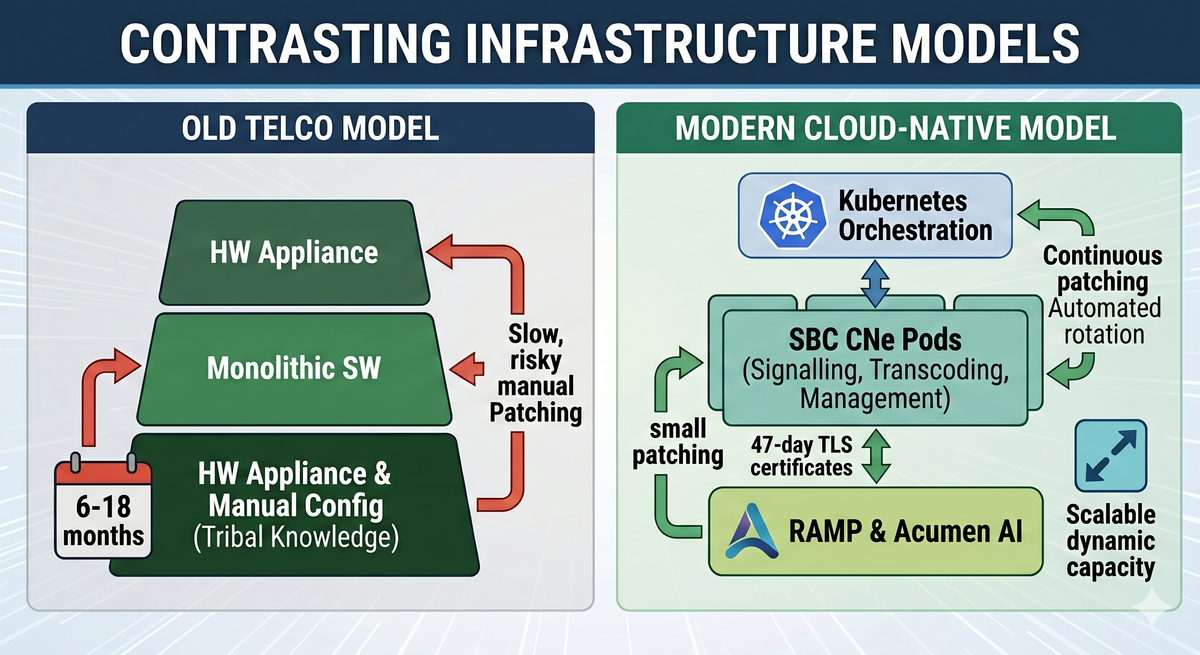
The Old Telco Infrastructure Model Is Breaking
Telco network upgrades have always been a slow, careful, and expensive process. Multi-year projects. Historically, mission-critical kit was installed in large racks and, where possible, left alone until a change was really needed. A full network software upgrade measured not in hours or days but in months — six to eighteen, by common industry reckoning.
I sat down with Matt Hurst, now Senior Director for Ribbon's AI and Automation practice, on the Teams Insider Podcast to unpack what that actually means, where it's genuinely useful, and where it's still hype. This article came from that, along with some further conversations. Many thanks to Ribbon for their ongoing support of the community.
The old model is breaking. The pressures have changed: telcos need to move faster to compete, and everyone — telco and enterprise alike — is under relentless pressure to stay patched and secure under new attacks, further accelerated by bad actors using AI.
- Security is harder than ever. These infrastructures are probed hourly. Running on "stable" firmware from last year isn't caution — it's exposure. Patching has to be continuous, and continuous patching can't be manual.
- Rollouts and Upgrades are too slow. A six-to-eighteen-month cycle to roll a change across a network or to deploy new infrastructure was acceptable when threats and competitors moved at the same pace. Neither does any more.
- TLS Certificate rules are coming fast. The rules around TLS certificates are about to make frequent, automated rotation a hard operational requirement rather than a best-practice aspiration.
To meet the need to move faster and be more secure, the telco industry has borrowed from the software world: containerisation, automation, and — increasingly — AI.
100-Day TLS Certificates Are Less Than a Year Away — Forcing the Need for Automation
In 2025, the CA/Browser Forum approved a phased reduction in the maximum lifetime of publicly trusted TLS certificates.
The schedule, each change landing on 15 March:
- March 2026: 200 days
- March 2027: 100 days
- March 2029: 47 days — with domain validation reuse dropping to just 10 days
That's roughly an eight-fold increase in renewal events. The certificate-management industry is talking about this loudly — but almost entirely as a generic web-server and enterprise-PKI problem. Far fewer people are connecting it to voice infrastructure, where certificates underpin the secure SIP and media connections between your SBCs, your trunk providers, and platforms like Microsoft Teams.
A caveat worth stating plainly: the CA/B Forum mandate covers publicly trusted certificates. A lot of internal telco and SBC infrastructure runs on internal PKIs — but the moment it interconnects with public services and cloud partners, public certificates come into play.
Manual certificate rotation across a fleet of voice nodes, eight times a year, is not survivable. The cert mandate may turn out to be the thing that pushes "automation is interesting" into "automation is non-negotiable."
What Is Containerisation?
If you've read this far, you'll likely know what a Session Border Controller (SBC) is, the device that sits at the edge of a voice network, securing and controlling SIP calls as they pass between networks. It started life as a physical device — a dedicated box you racked and cabled (I've deployed quite a few in my time).
The first evolution was virtualisation: the same software stack running as a Virtual Network Function (VNF), often on a commodity server rather than purpose-built hardware. Or even in a public or private cloud. In Skype for Business times, we did a lot of these on Enterprise VMware deployments.
If you want more capacity, you deploy more SBCs.
Containerisation breaks that monolith apart. Matt's analogy is the best I've heard for it:
Think about building a house. You build the structure, the rooms, the plumbing, the electrics, the drainage — all for one purpose, and you live in it. That's the traditional model. Compare that to a hotel. The infrastructure's already there — plumbing, electrics, broadband, all of it. You just rent a room. You don't have to build the hotel. And you can rent 50 rooms for one night and 10 rooms for ten nights. You've got flexibility and scaling, and you never touch the underlying infrastructure.
That's containerisation. Take the SBC and break it into modules — pods (Kubernetes terminology) — where one handles signalling, one handles transcoding, and one handles management. When you need more capacity, you scale just the pods that need it rather than the whole box.
Transcoding is the classic example, and it's one I remember well from my own infrastructure-speccing days. You'd size for peak concurrency — this PBX talking to that one, this codec to Skype — and buy a physical kit to handle the worst-case spike. Most of the time, that capacity sat idle, but you had to build for the peak.
In a containerised world, the automation layer monitors real traffic patterns, learns that you get a transcoding spike at certain times of day, spins up transcoding pods to meet the demand, and spins them back down when demand fades. You stop constantly paying for the peak you only hit occasionally.
Who or what manages all those pods? That's Kubernetes. If containers are the rooms in Matt's hotel, Kubernetes is the hotel manager — the orchestration layer that decides how many rooms to open, books guests into them, notices when one has a problem and quietly moves people to another, and closes rooms down when they're not needed.
It started life as an internal Google project and is now an open, vendor-neutral standard stewarded by the Cloud Native Computing Foundation (CNCF). It's a common platform in many Public and Private Clouds.
Public, Private, or Both — Without the Lock-In
A common assumption is that "containerised" means "public cloud." It doesn't have to.
Because Kubernetes is an industry-standard architecture available in public cloud and private environments, the same containerised function runs in either or both. A telco can start a new market on public cloud because it's faster and cheaper to stand up, then later move that workload to a private instance as volumes grow and the economics shift. Same architecture, same tooling, no forklift rebuild.
This is proving to be a genuine jump-off point. When an operator breaks into a new region — France, Germany, Spain — the old approach meant procuring colo space or building a data centre: a year or more before you serve a single customer. Spinning up in-country on public cloud gets you live in weeks, lets you prove the market when you don't yet know if it's 1,000 customers or 10,000, and keeps the option open to repatriate to private infrastructure later. Crucially, the traditional hardware, virtual, and containerised platforms all perform the same function — so they coexist, and migration is incremental rather than a big bang.
This Is Where the Voice Industry Is Going — Not Just Ribbon
It's fair to be sceptical of a vendor telling you their architecture is the future. So it's worth saying clearly: this shift is industry-wide and well past the point of debate.
Kubernetes has become the de facto standard for running containerised workloads. The CNCF, which stewards the project, now describes it as the "operating system" of modern infrastructure, with 82% of container users running it in production (up from 66% in 2023) and 98% of organisations having adopted cloud-native techniques. In telco specifically, that shift is well underway: virtually every 5G network function vendor now ships a containerised offering, and industry bodies like LF Networking are actively building cloud-native telco blueprints (Nephio, the 5G Super Blueprints, the Cloud Native Telco Initiative). The physical → virtual → containerised journey is the accepted arc of the whole industry, told by the likes of VMware/Broadcom, Red Hat, SUSE and Canonical, not just Ribbon.
Containerisation, GitOps, CI/CD pipelines and canary deployments are not Ribbon inventions. They are proven, CNCF-standard practices that the broader IT world has run for years. What carrier-grade voice vendors like Ribbon are doing is applying that proven toolchain to a real-time, mission-critical workload that, unlike a web app, cannot tolerate unpredictable latency or dropped calls.
Where Ribbon Fits
Ribbon's cloud-native voice stack is three parts: SBC CNe (the Session Border Controller itself, Cloud Native Edition), PSX CNe (the policy and routing engine), and RAMP (the management, analytics and licensing platform) — all fully containerised and deployable across Kubernetes, Red Hat OpenShift or AWS EKS, so the same software runs in public, private or hybrid clouds. It's the same SBC lineage Ribbon has run in the world's largest carrier networks for years, re-architected as microservices rather than a monolith.
Tying it together is Acumen, the AIOps and automation platform Ribbon launched in late 2025. Acumen is where the three threads of this article — containerisation, automation and AI — actually meet in a product: it runs the deployment-and-upgrade pipeline (download, security scan, digital twin, test, canary, audit), gives a unified view across both Ribbon and third-party components, and includes no-code tools for building the kind of operational AI agents and chatbots described above. The carrier-grade detail is the point: this is the proven cloud-native toolchain applied to a workload that can't drop a call.
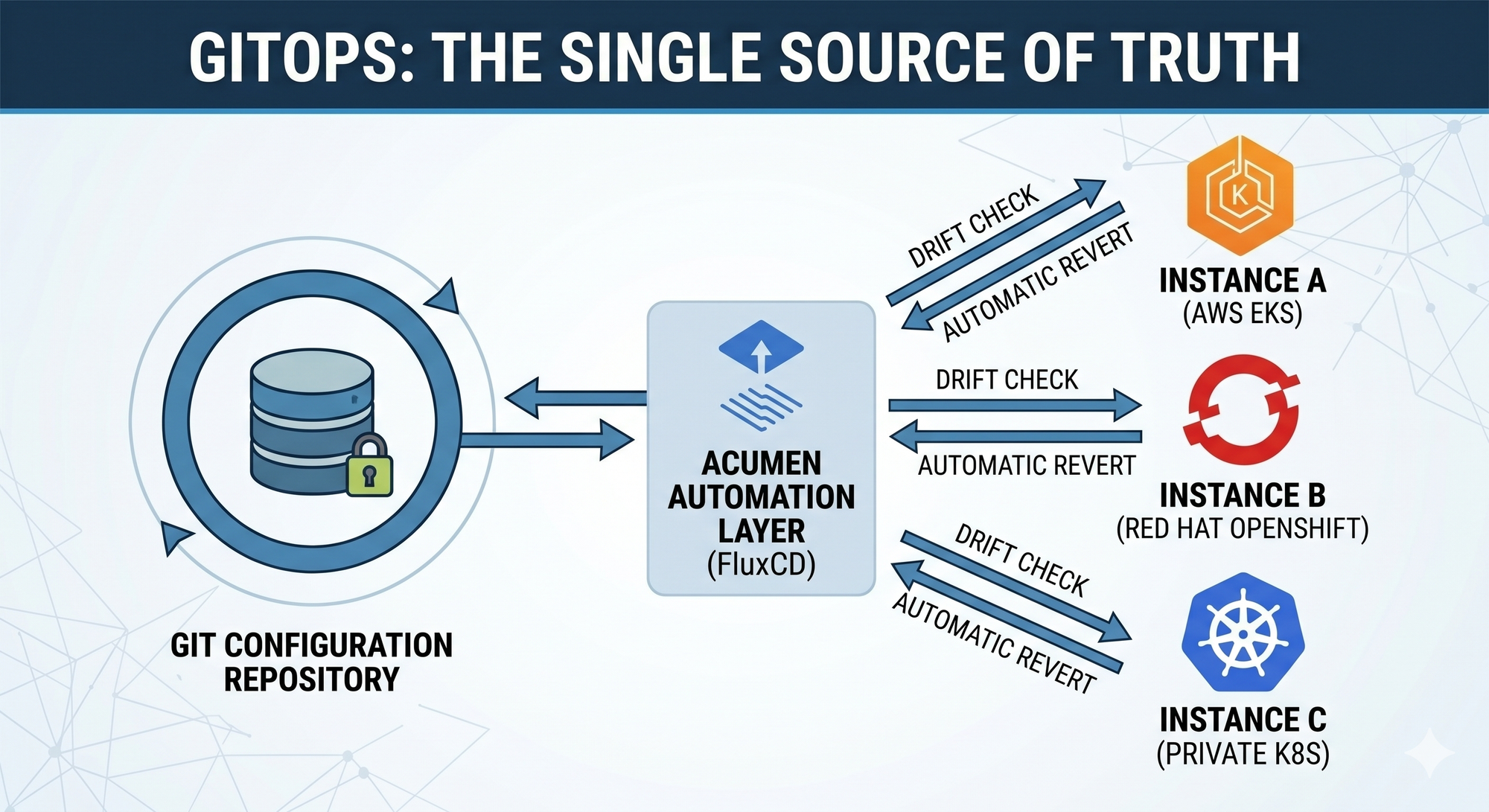
An Operational Win: Single Source of Truth
Containerisation gets the headlines, but it's the operational change that matters most.
In the old world, you configured each device by hand for its site, customised it, took a backup, and hoped. If the box died, you restored the backup, made some tweaks, and brought it back. The "documentation" of your network was a backup taken six months ago and a couple of engineers' memories.
In a containerised, GitOps-driven world, the configuration lives in Git as the single source of truth. Network components replicate from it; if one dies, the system automatically spawns a replacement that pulls the correct config from the central repository. No per-site hand-configuration. This is "infrastructure as code" in its truest sense — not "I documented the infrastructure" but "the configuration is the infrastructure, and they are mapped to each other."
Better still, the automation can run periodic drift checks against the live network — flagging (or automatically reverting) any manual change that's crept in. For anyone who's lived with configuration drift across a fleet of SBCs, that alone is worth the price of admission.
Two Levels of Automation
It helps to separate automation into two layers, because they're often conflated.
Level 1: Deployment
Standard Helm charts and templates deploy a function: define the variables, point at the template, and the system stands the pods up in seconds, calculating exactly how many resources are required for your sizing. Under the hood, this uses the standard CNCF toolchain—Helm for packaging and FluxCD for reconciling the live state against the Git repository. An upgrade can be as simple as pointing the manifest at a new chart version and letting the system converge.
Level 2: Operations
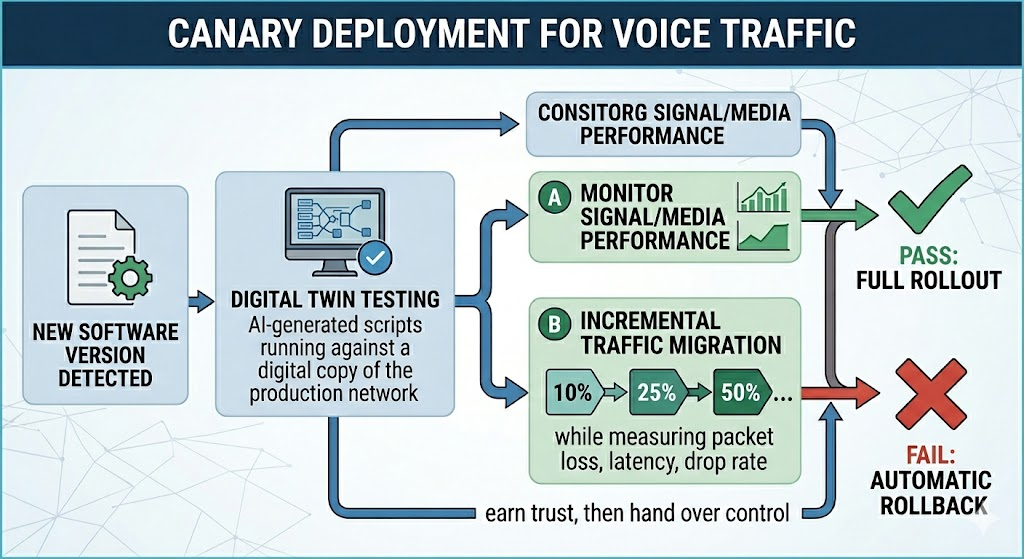
This is where carrier-grade engineering earns its keep. Ribbon's automation platform, Acumen, wraps the lifecycle into a rigorous pipeline: software download, security scanning, environment configuration, digital twinning, automated testing, canary rollout, and post-production auditing.
The canary upgrade process is particularly significant. Rather than shifting all traffic to a new version simultaneously and hoping for the best, an automated canary rollout:
- Detects when the vendor publishes a new version and pulls it into your environment.
- Spins up a new instance alongside the running one.
- Runs automated test suites against it using real traffic profiles.
- Gracefully migrates live traffic only once the new version passes all checks.
- Drains and tears down the old version, keeping a rollback option immediately available.
This process is incremental by design. Customers typically start with each step set to manual: they receive a notification that a new version is available, manually trigger the spin-up, review the test results, and explicitly approve the migration. As confidence builds, these steps are progressively automated until the system simply reports: "You're upgraded, here's the validation report, let us know if you want to revert." That "earn trust, then hand over control" path is exactly how network autonomy should be approached.
Canary deployments, GitOps, and progressive delivery are standard patterns in the Kubernetes world. Ribbon's additions are the carrier-grade pieces — its own Horizontal Pod Autoscaler tuned for voice rather than the native Kubernetes one, and digital-twin call testing that validates against the real protocols a voice network depends on.
3 Actual AI Use Cases
Matt was refreshingly blunt: "AI" is a tagline plastered over everything right now, and the market is tiring of it. The interesting question isn't whether AI is transformative in the abstract — it's which concrete, boring, valuable things it can do today. Three stood out.
- Test automation with a digital twin. The system learns a network's real traffic patterns over an extended period, distils them down to (say) the 500 most typical call flows — internal, external, refer, call hold — and auto-generates test scripts. Before a new software load goes anywhere near production, it's run against a digital twin of the network and tested with traffic that actually represents how this customer's network behaves.
- A chatbot for the thinning skills bench. This one resonated because the classic SBC management skill set is getting thin on the ground — I've seen enterprises where two people understand the SBC estate, and otherwise it's a black hole. With AI and domain knowledge, the engineer doesn't need to be a VoIP expert; the system guides them on problems and solutions.
- Full-stack root cause. Telco infrastructure is a stack of dominoes — an application-layer call-quality problem might actually be a congested or failed router two layers down. AI that can look across the whole stack can point the technician at the most probable cause ("this router just spiked on memory — start there") rather than leaving them to work down from the symptom.
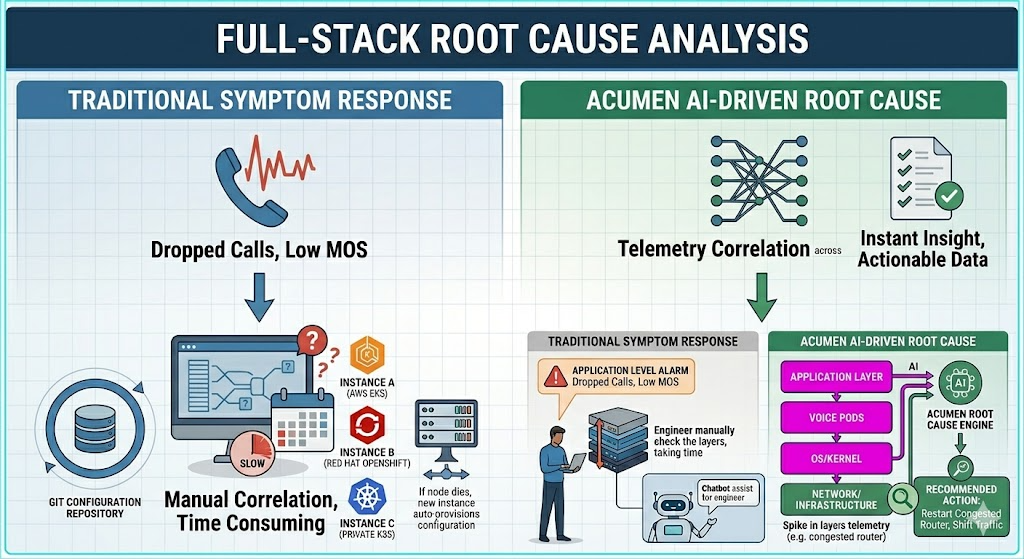
The common thread: this is AI doing the unglamorous operational grind — at 2 am, without needing a coffee first — so that scarce senior engineers are freed for higher-value work. That's the version of the AI story that survives contact with a sceptical operations team.
It's a Journey, Not a Big Bang
The temptation with all of this is to imagine a moonshot. Every operator and enterprise I speak to that's doing it well started the opposite way.
Matt described Ribbon's engagement as deliberately consultative: start with the business problem — are you chasing revenue, new markets, efficiency, or visibility? — then pick a small, low-risk, high-confidence automation, prove the ROI, and build from there. Once an operator sees the first win and benefits, the appetite to scale follows naturally. The initial motivations are usually different:
- Telcos are mostly driven by agility and competition — entering new markets quickly, defending against eroding voice-minute margins from OTT players, and building new services.
- Large enterprises — particularly in finance and FinTech - who still want to run their own voice infrastructure — are mostly driven by security and operations: keeping pace with patching, satisfying SOC 2 Type 2 and similar regimes that demand proven, not merely documented, version and patch management, and de-risking infrastructure that too often sits on a fragile island of tribal knowledge.
The rebuild of telco voice to an agile containerised infrastructure isn't a question of if any more — the threats, the competition and the certificate clock have made it a requirement. It's only a question of how soon you start and how fast you can move.
This article grew out of a Teams Insider Podcast conversation with Matt Hurst of Ribbon. You can watch the full episode [here]. Thanks to Matt for the conversation, and to Ribbon for supporting Empowering.Cloud. Find out more about Ribbon's portfolio of Cloud Native Containerised solutions and AIOps & Automation platform at ribboncommunications.com
Comments ()